Language detection using NLP
Text classification is a process of classifying sentences or documents into pre-defined categories. Language detection is no different in terms of the method. During language detection, we classify text into categories, these categories however are our pre-defined languages.
Most of modern NLP frameworks use so called "text embedding" method where the text is being transformed into numerical vector and evaluated within mutli-dimensional space, other use maxent or naive bayes algorithms to evaluate the data.No need to be an expert
You no longer need to be an NLP expert nor programmer to perform language detection on your own! You might use TEXT2DATA service with Excel Add-In or Goggle Sheets add-on to do it in literally 5 minutes!Detecting over 50 languages in simple steps
Further in this article you will learn how to detect over 50 languages using TEXT2DATA service. Following languages are currently supported:
Simple steps
1. Once you register at text2data.com, simply go to your admin panel.
2. Under "Api classification models", find the drop-down list with pre-trained model list.
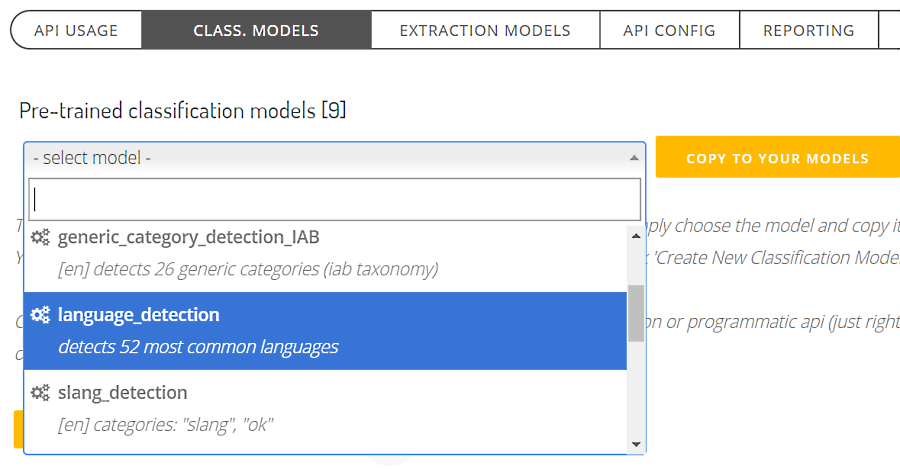
3. Select "language_detection" and copy it to your classification models.
4. Install our Excel Add-In or Google Sheets Add-on.
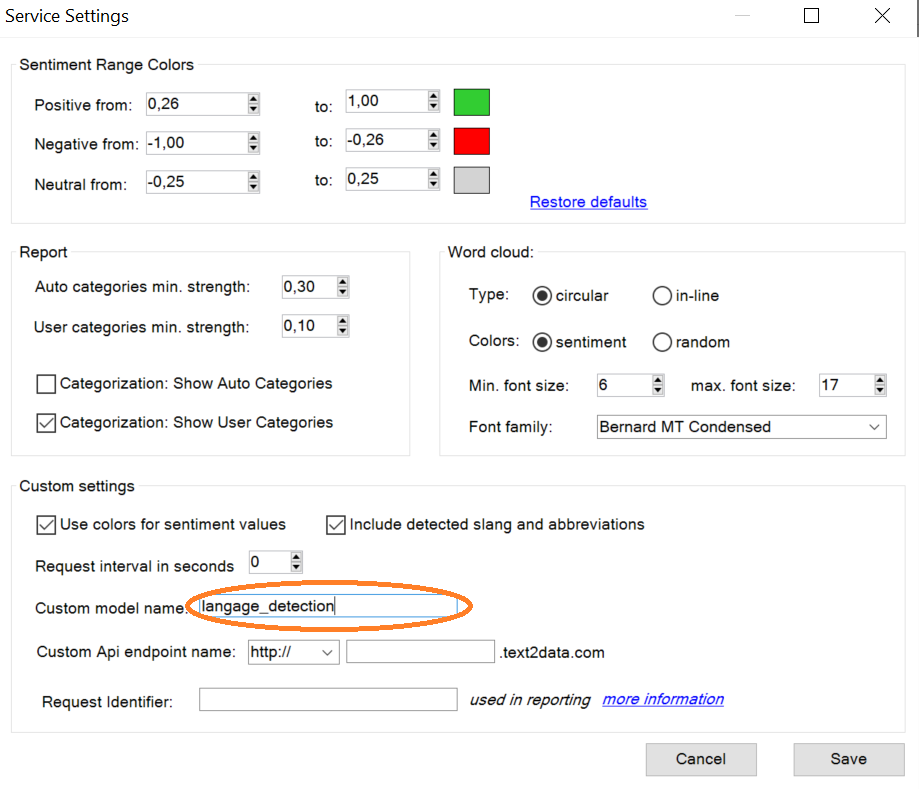
5. If you have already any other custom models created, set "language_detection" model as default in TEXT2DATA admin panel or set the model name in Excel Add-In or Google Sheets add-on in service settings options.
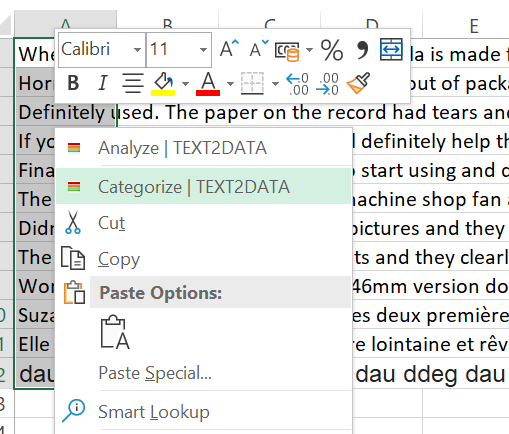
6. Finally, right click/select text and click "Categorize"
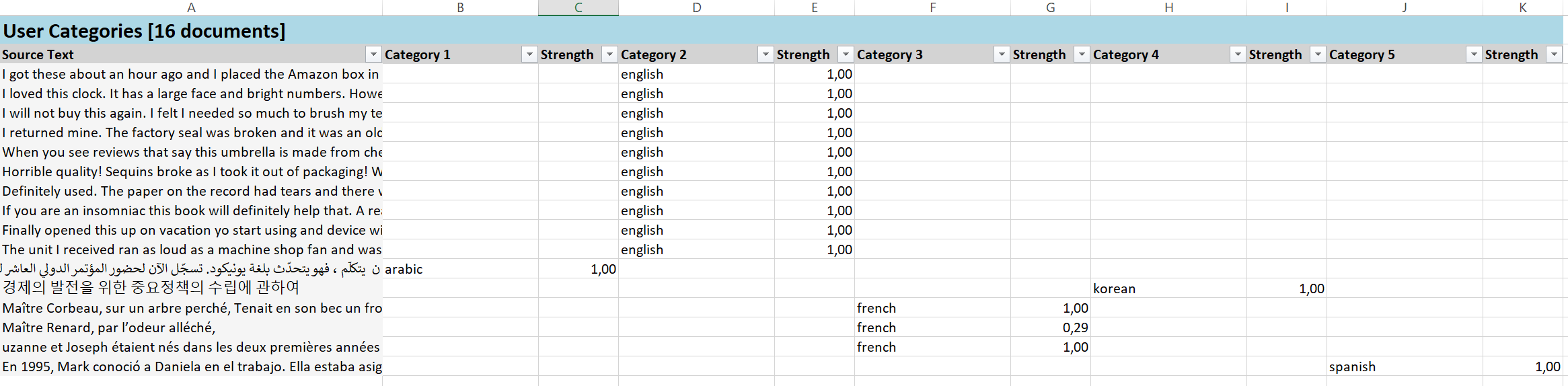
Once the analysis is done, open report from the right-hand side task pane.You should see the list of assigned languages next to analyzed documents. If we are not entirely sure of what language is to be detected, you will see multiple results per one document along with its probability score "category strength" (ranges from 0-1)
Using other custom models
Using other custom models at TEXT2DATA is similar, just follow the above steps with different model selected.
Do not forget to sign up to text2data.com. Click on the image below and start testing out our sentiment analysis and text analytics tool.

