What is text extraction?
Text extraction is the process of extracting pre-defined entities (types of information) from the text content. The best technique for that is using Natural Language Processing (NLP) combined with custom regular expressions (Regex).
TEXT2DATA service allows you to build your own custom extraction models using our online model builder tool.
Apart from that, our users can use our ready-to-use publicly available extraction models. In order to do that, the user only needs to select the model from the list and copy it to his own custom extraction models. This functionality is available in user admin panel.
Publicly available extraction models
The list below contains description of all currently available extraction models at TEXT2DATA:
-
Basic entity extraction model
extracts basic entities: LOCATION, PERSON, ORGANIZATION
-
Extended entity extraction model
extracts: LOCATION, PERSON, ORGANIZATION, MONEY, PERCENT, DATE, TIME
-
Email extraction model
extracts email addresses
-
HTML to text extraction
extracts clean, easy to read text content from HTML
-
Phone number extraction model
extracts phone numbers from text
-
Price extraction model
extracts prices in following currencies: USD, EUR and GBP
-
Sentence extraction model
extracts sentences from text
-
Url extraction model
extracts urls from text
-
US address extraction model
extracts US addresses from text contents
-
Email-phone-address extraction model
extracts email/phone/address in one request
-
Number extraction model
extracts all numbers from text
At TEXT2DATA we are constantly working on adding new models and improving existing ones, so keep checking for the updates.
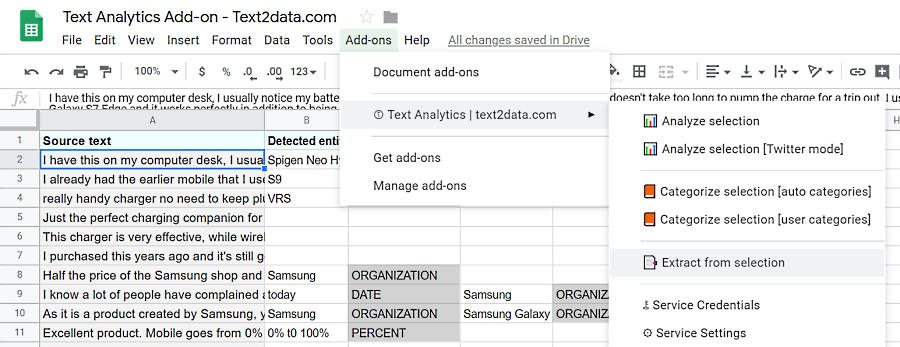
To use the above models in our Excel Add-In or Google Sheets add-on, simply copy an model to your model list at your TEXT2DATA user panel and click "Extract" option on selected text in Excel or Google Sheets add-on.
1. Copy the extration model at TEXT2DATA user panel
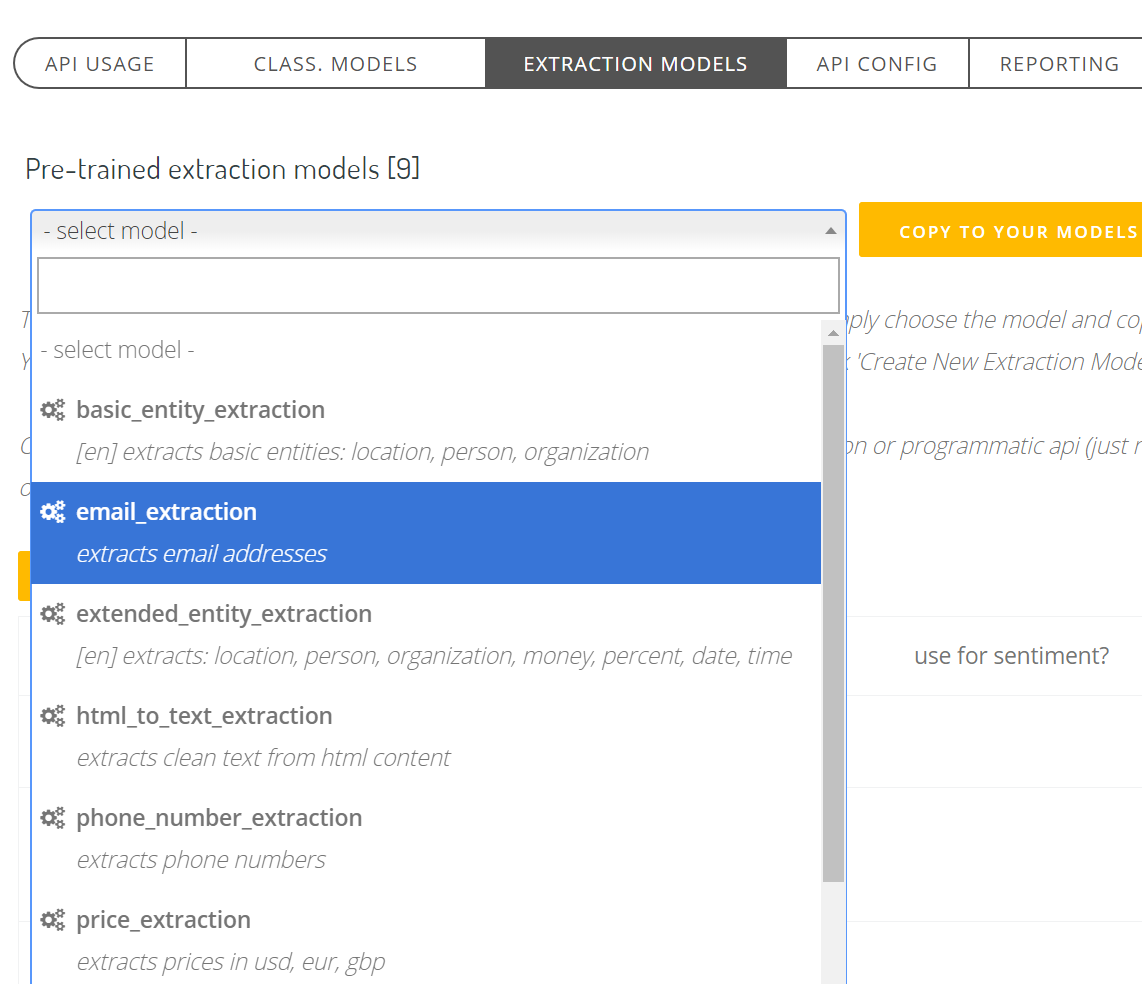
2. Run extraction in Excel Add-In
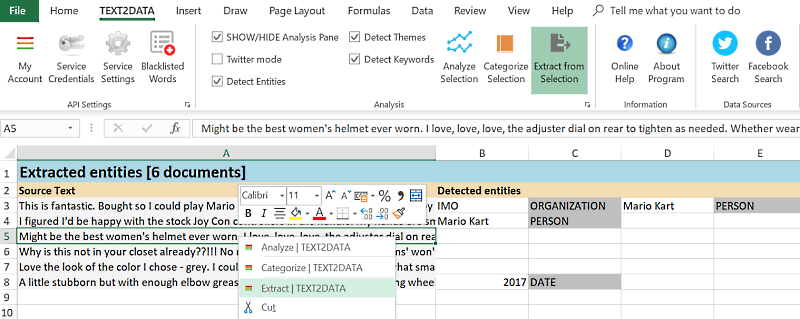
3. Run extraction in Google Sheets add-on